
From Wix to Korail: how I import 500+ pages cleanly — Part 2
Migrating hindouisme.org: custom Node.js scraper, Korail importer, JSON → React blocks.
In Part 1, I explained why I chose to rebuild hindouisme.org. Picking it was the easy part. The real challenge started here:
How do you migrate a Wix site with nearly 500+ pages without losing content, images, and links — and without months of copy‑pasting?
That’s what I cover in Part 2: the move from Wix → Korail.
The Wix problem
Wix is a gilded cage. It lets you build fast, but:
- no complete export API,
- no JSON or XML dump,
- each page is client‑rendered, stuffed with inline styles and nested divs.
In short: no simple “export → import”.
The scraper: coding my own escape hatch
So I wrote a custom Node.js scraper. Goal: turn a locked‑down old site into a clean dataset.
We preserve the original structure (headings, lists, links) to ensure faithful rendering.
// korail-scraper/scrape-to-json.js (condensed excerpt)
import { chromium } from 'playwright'
import TurndownService from 'turndown'
import { gfm } from 'turndown-plugin-gfm'
// 1) Fetch dynamic HTML
async function renderPage(url) {
const browser = await chromium.launch({ headless: true })
const page = await browser.newPage()
await page.setUserAgent('Mozilla/5.0 KorailScraper/1.0')
await page.goto(url, { waitUntil: 'networkidle' })
await page.waitForTimeout(1000)
const html = await page.content()
const title = await page.title()
await browser.close()
return { html, title }
}
// 2) Fallback logic: <article> → else <main> → else cleaned <body>
function extractMainHtml(fullHtml) {
const bodyStart = fullHtml.indexOf('<body')
const bodyEnd = fullHtml.lastIndexOf('</body>')
const body = bodyStart !== -1 && bodyEnd !== -1 ? fullHtml.slice(bodyStart, bodyEnd + 7) : fullHtml
const pick = (re) => (body.match(re)?.[0] || '')
const article = pick(/<article[\s\S]*?<\/article>/i)
if (article) return article
const main = pick(/<main[\s\S]*?<\/main>/i)
if (main) return main
return body.replace(/^<body[^>]*>/i, '').replace(/<\/body>$/i, '')
}
// 3) Convert HTML → Markdown preserving headings/lists/links
function htmlToMarkdown(innerHtml) {
const turndown = new TurndownService({ headingStyle: 'atx', codeBlockStyle: 'fenced' })
turndown.use(gfm)
return turndown.turndown(innerHtml)
}
# Single URL
node scrape-to-json.js --url https://www.hindouisme.org/who-is-ganesha
# URLs file + base
node scrape-to-json.js --file urls.txt --base https://www.hindouisme.org
Stack used
- Puppeteer — fetch dynamic HTML (lazy images, scripted content)
- Cheerio — parse/clean the DOM before export (remove inline styles/wrappers)
- Turndown + GFM — HTML → Markdown preserving headings, lists, links
- Final export as JSON
Process steps
-
Crawl all URLs
- The script scans the sitemap when available; otherwise it walks internal links recursively.
- Result: an exhaustive list of ~500 pages.
-
Extract content
- For each page: title, body text, images, internal/external links.
- Clean tags (
<div style="…">→ removed; keep headings, paragraphs, lists, images).
-
Structure as JSON Sample output:
{ "url": "https://www.hindouisme.org/who-is-ganesha", "title": "Who is Ganesha?", "content": "<h1>…</h1><p>…</p>", "images": [ {"src": "/uploads/ganesha.jpg", "alt": "Ganesha"}, {"src": "/uploads/temple.jpg", "alt": "Hindu temple"} ], "links": [ "https://www.hindouisme.org/dharma", "https://www.hindouisme.org/karma" ] }
👉 At this point, I had a complete snapshot of the site: clean, clear, and usable.
The Korail importer
Once the dataset was generated, I needed to ingest it into Korail. That’s where the Korail importer comes in.
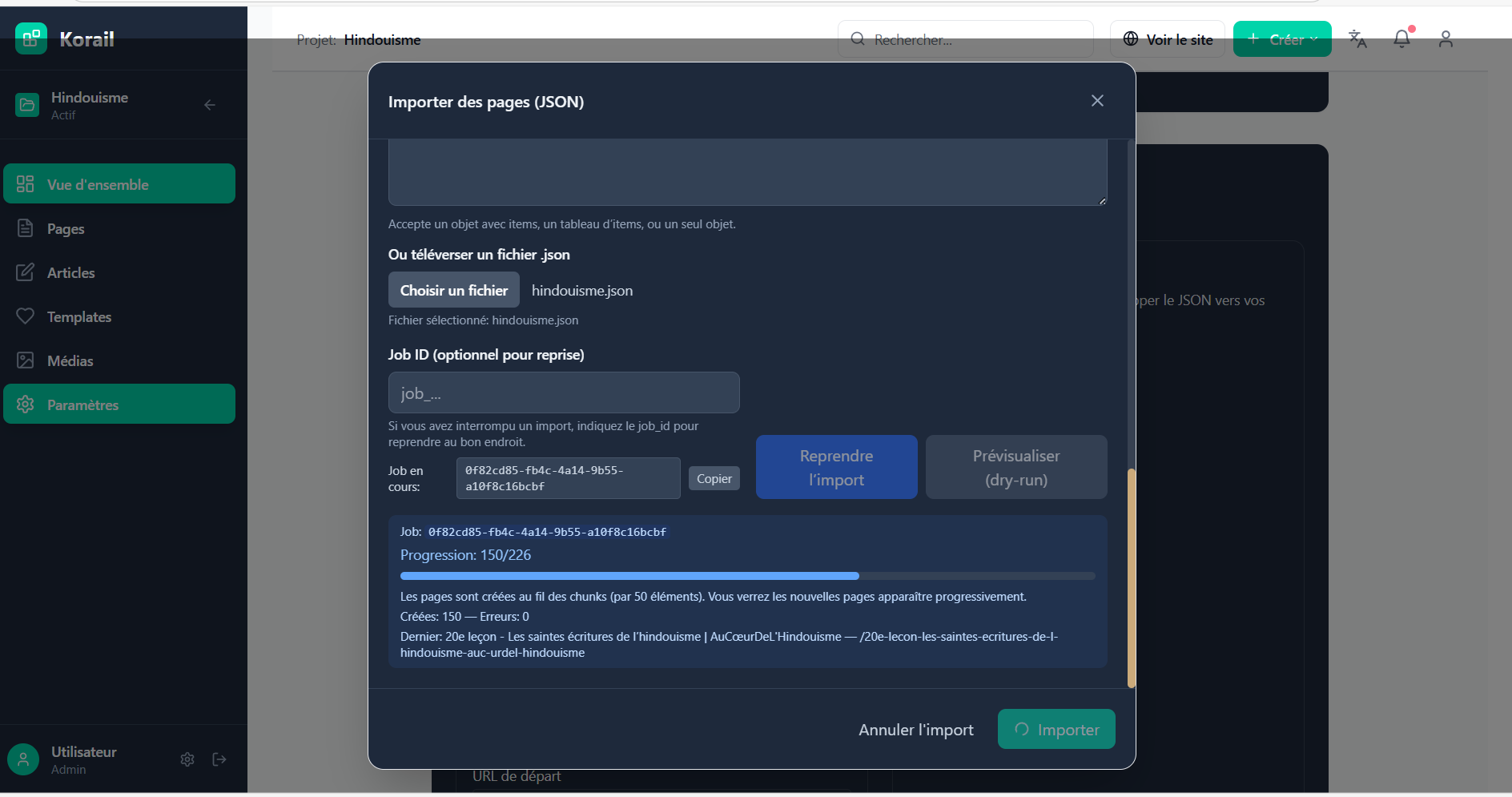
Import steps
-
Read the JSON: each object is treated as a future page/post.
-
Insert into Supabase (my Postgres):
pages(orposts) table →title,slug,content,status.mediatable → download images locally + upload to Supabase Storage.linkstable → preserve internal relations.
-
Convert to React blocks:
- Each page is split into blocks (
HeadingBlock,ParagraphBlock,ImageBlock, etc.). - Result: content becomes editable block by block in Korail.
- Each page is split into blocks (
-
Auto‑optimize:
- Images → renamed, compressed, with
altgenerated by AI (Vision). - SEO → generate
meta_titleandmeta_descriptionvia GPT‑4 mini. - URLs → rewritten cleanly, no
/page-123.
- Images → renamed, compressed, with
Part 3: what’s next?
Now that the content is imported into Korail, the real challenge begins: how do we give a clear architecture to 500+ pages?
- Rethink navigation: categories, sub‑sections, pillar pages.
- Avoid the maze effect where users get lost in dozens of menus.
- Lay the foundations for vector search — not to replace navigation, but to augment it, offering two complementary entry points:
- Explore by structure (clear sections, logical hierarchy).
- Explore by meaning (ask freely and get a precise answer).
👉 That’s precisely what I’ll explore in Part 3: how to turn a mass of content into a readable, logical, intelligent site — through a redesigned architecture augmented by vector search.
Related posts
When 5,000 Years of History Meet New Technologies — Part 1
Rebuilding hindouisme.org and creating Korail: a vector-native CMS with React, Supabase, SEO, performance, simplicity.
Why I Dumped WordPress (and Don’t Even Get Me Started on Wix)
Why I build all my sites with Next.js, React, Vercel and Supabase
Why I Created Korail
Why I created Korail, with built‑in vector search à la Perplexity.
Marie Fa
Full-stack developer from Québec, based in Bacalar — sailing between turquoise water and lines of code.
Founder of Murmure & Korail, SocialRally and Adorable Sailing.