
De Wix à Korail : comment j’importe 500+ pages proprement — Partie 2
Migration de hindouisme.org : scraper Node.js, importateur Korail, JSON → blocs React.
Dans la Partie 1, je racontais pourquoi j’ai choisi de reconstruire hindouisme.org. Mais choisir, c’était la partie facile. Le vrai défi commençait ici :
Comment migrer un site Wix de près de 500 + pages sans perdre contenu, images et liens, et sans passer des mois à copier-coller ?
C’est ce que j’explique dans cette Partie 2 : le passage de Wix → Korail.
Le problème Wix
Wix est une cage dorée. Il permet de créer vite, mais :
- aucune API d’export complète,
- pas de dump JSON ou XML,
- chaque page est rendue côté client, bourrée de styles inline et de div imbriquées.
Bref : impossible de faire “exporter → importer”.
Le scraper : coder ma propre sortie de secours
J’ai donc écrit un scraper Node.js sur mesure. Objectif : transformer un vieux site verrouillé en un dataset propre.
Nous respectons la structure d’origine (titres, listes, liens) pour garantir un rendu fidèle.
// korail-scraper/scrape-to-json.js (extrait condensé)
import { chromium } from 'playwright'
import TurndownService from 'turndown'
import { gfm } from 'turndown-plugin-gfm'
// 1) Récupérer le HTML dynamique
async function renderPage(url) {
const browser = await chromium.launch({ headless: true })
const page = await browser.newPage()
await page.setUserAgent('Mozilla/5.0 KorailScraper/1.0')
await page.goto(url, { waitUntil: 'networkidle' })
await page.waitForTimeout(1000) // laisser charger les images lazy
const html = await page.content()
const title = await page.title()
await browser.close()
return { html, title }
}
// 2) Extraire la zone principale: <article> → sinon <main> → sinon <body> nettoyé
function extractMainHtml(fullHtml) {
const bodyStart = fullHtml.indexOf('<body')
const bodyEnd = fullHtml.lastIndexOf('</body>')
const body = bodyStart !== -1 && bodyEnd !== -1 ? fullHtml.slice(bodyStart, bodyEnd + 7) : fullHtml
const pick = (re) => (body.match(re)?.[0] || '')
const article = pick(/<article[\s\S]*?<\/article>/i)
if (article) return article
const main = pick(/<main[\s\S]*?<\/main>/i)
if (main) return main
return body.replace(/^<body[^>]*>/i, '').replace(/<\/body>$/i, '')
}
// 3) Convertir en Markdown en conservant titres/listes/liens
function htmlToMarkdown(innerHtml) {
const turndown = new TurndownService({ headingStyle: 'atx', codeBlockStyle: 'fenced' })
turndown.use(gfm)
return turndown.turndown(innerHtml)
}
# URL unique
node scrape-to-json.js --url https://www.hindouisme.org/qui-est-ganesha
# Fichier de liens + base
node scrape-to-json.js --file urls.txt --base https://www.hindouisme.org
Stack utilisée
- Puppeteer — récupérer le HTML dynamique (lazy images, scripts, etc.).
- Cheerio — parser/nettoyer le DOM avant export (suppression de styles inline/wrappers inutiles).
- Turndown + GFM — conversion HTML → Markdown en conservant titres, listes, liens.
- Export final en JSON.
Étapes du process
-
Crawler toutes les URLs
- Le script scanne le sitemap quand dispo, sinon il parcourt le site récursivement via les liens internes.
- Résultat : une liste exhaustive des ~500 pages.
-
Extraction du contenu
- Pour chaque page : titre, corps de texte, images, liens internes/externes.
- Nettoyage des balises (
<div style="…">→ supprimé, seuls les titres, paragraphes, listes, images sont conservés).
-
Structuration en JSON Exemple de sortie :
{ "url": "https://www.hindouisme.org/qui-est-ganesha", "title": "Qui est Ganesha ?", "content": "<h1>…</h1><p>…</p>", "images": [ {"src": "/uploads/ganesha.jpg", "alt": "Ganesha"}, {"src": "/uploads/temple.jpg", "alt": "Temple hindou"} ], "links": [ "https://www.hindouisme.org/dharma", "https://www.hindouisme.org/karma" ] }
👉 À ce stade, j’avais une photographie complète du site : propre, claire, exploitable.
L’importateur Korail
Une fois le dataset généré, il fallait l’ingérer dans Korail. C’est là que l’importateur Korail entre en jeu.
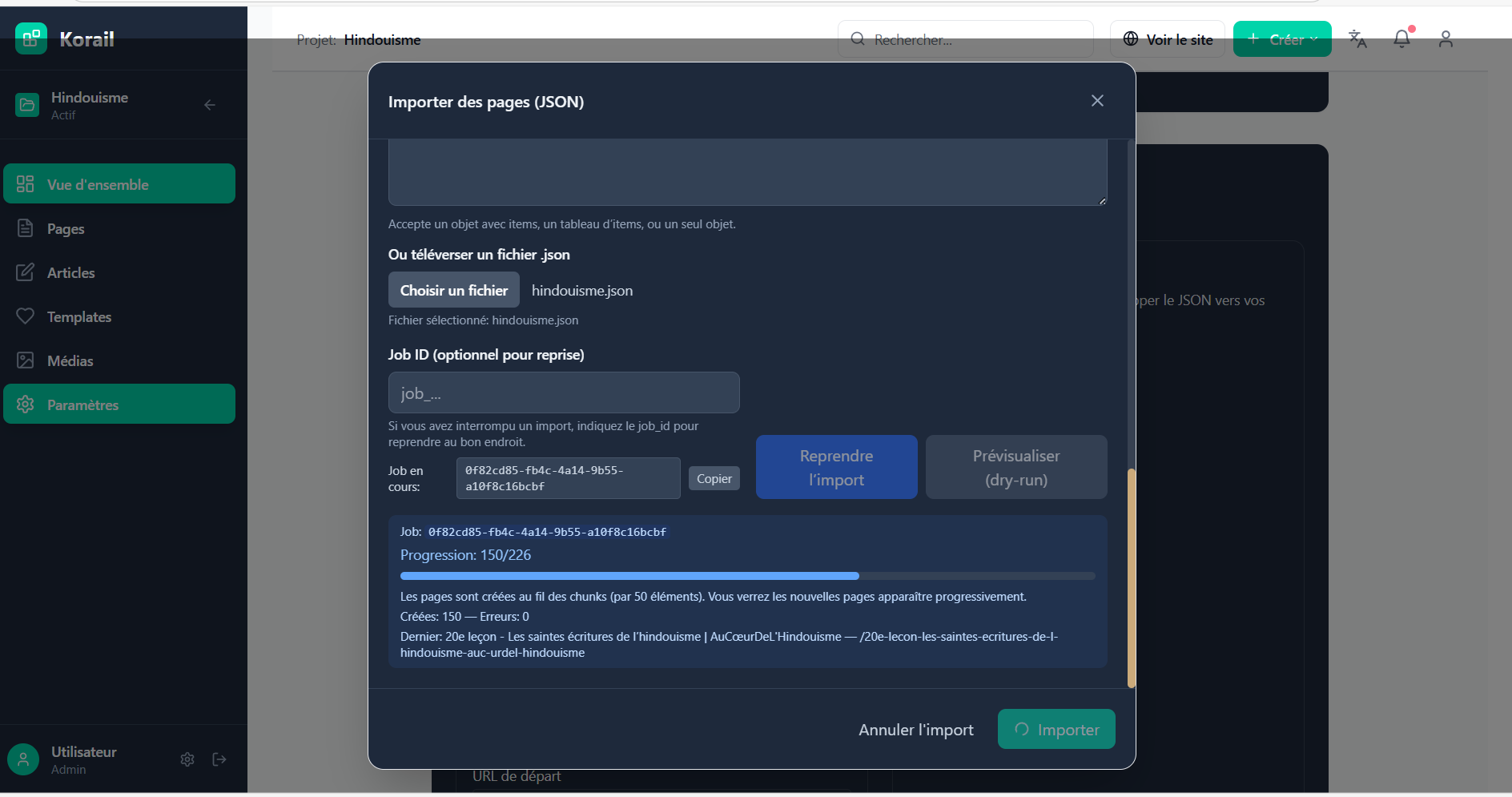
Étapes de l’import
-
Lecture du JSON : chaque objet est interprété comme une future page/article.
-
Injection dans Supabase (ma base Postgres) :
- Table
pages(ouposts) →title,slug,content,status. - Table
media→ téléchargement des images en local + upload dans Supabase Storage. - Table
links→ conservation des relations internes.
- Table
-
Conversion en blocs React :
- Chaque page est découpée en blocs (
HeadingBlock,ParagraphBlock,ImageBlock, etc.). - Résultat : le contenu devient éditable bloc par bloc dans Korail.
- Chaque page est découpée en blocs (
-
Optimisation auto :
- Images → renommées, compressées, avec
altgénéré par l’IA (Vision). - SEO → génération de
meta_titleetmeta_descriptionvia GPT-4 mini. - URLs → réécrites proprement, sans
/page-123.
- Images → renommées, compressées, avec
Exemple concret
Une vieille page Wix :
<div style="font-size:22px;color:red">Qui est Ganesha ?</div>
<p>Ganesha est …</p>
→ devient dans Korail :
{
"blocks": [
{"type": "HeadingBlock", "content": "Qui est Ganesha ?", "level": 1},
{"type": "ParagraphBlock", "content": "Ganesha est …"}
]
}
Et surtout : éditable directement dans le dashboard Korail.
Pourquoi ça change tout
Ce n’est pas juste un import unique. Chaque ligne de code du scraper et de l’importateur est maintenant intégrée à Korail.
Résultat :
- Je peux importer un site Wix, WordPress ou Squarespace en quelques minutes.
- Le contenu devient structuré en blocs React, donc modifiable facilement.
- Les images sont stockées proprement avec titres/alt automatiques.
- Le site est SEO ready dès le jour 1.
👉 Hindouisme.org n’est que le premier exemple. N’importe qui peut déjà tester Korail sur mykorail.com et voir comment ce workflow simplifie la vie.
Partie 3 : et après ?
Maintenant que le contenu est importé dans Korail, le vrai défi commence : comment donner une architecture claire à plus de 500 pages ?
- Repenser la navigation : catégories, sous-sections, pages‑piliers.
- Éviter l’effet labyrinthe où l’utilisateur se perd dans des dizaines de menus.
- Poser les fondations de la recherche vectorielle — non pas pour remplacer la navigation, mais pour l’enrichir, afin de proposer deux portes d’entrée complémentaires :
- Explorer par structure (rubriques claires, hiérarchie logique).
- Explorer par sens (poser une question librement et obtenir une réponse précise).
👉 C’est exactement ce que je vais explorer dans la Partie 3 : comment transformer une masse de contenu en un site lisible, logique et intelligent, grâce à une architecture repensée et augmentée par la recherche vectorielle.
📅 Première démo publique : août 2025 🎯 Objectif : montrer hindouisme.org importé dans Korail, avec navigation repensée + premiers tests vectoriels.
En attendant, explorez Korail et suivez le blog : mykorail.com/korail/fr/blog.
Articles liés
Quand 5000 ans d’histoire rencontrent les nouvelles technologies — Partie 1
Refonte de hindouisme.org et naissance de Korail : CMS vectoriel, React, Supabase, SEO, performance, simplicité.
Pourquoi j’ai largué WordPress (et Wix n’en parlons même pas)
Pourquoi je construis tous mes sites avec Next.js, React, Vercel et Supabase
Pourquoi j'ai créé Korail
Pourquoi j’ai créé Korail, avec la recherche vectorielle intégrée façon Perplexity.
Marie Fa
Développeuse full-stack québécoise installée à Bacalar, je navigue entre eau turquoise et lignes de code.
Fondatrice de Murmure et Korail, SocialRally et Adorable Sailing.