
De Wix a Korail: cómo importo 500+ páginas de forma limpia — Parte 2
Migración de hindouisme.org: scraper Node.js a medida, importador de Korail, JSON → bloques React.
En la Parte 1, conté por qué elegí reconstruir hindouisme.org. Pero elegir era la parte fácil. El verdadero reto empezaba aquí:
¿Cómo migrar un sitio de Wix con casi 500+ páginas sin perder contenido, imágenes y enlaces, y sin pasar meses copiando y pegando?
Esto es lo que explico en esta Parte 2: el paso de Wix → Korail.
El problema de Wix
Wix es una jaula dorada. Permite crear rápido, pero:
- no hay una API de exportación completa,
- no hay volcado JSON o XML,
- cada página se renderiza del lado del cliente, llena de estilos inline y divs anidadas.
En resumen: imposible hacer “exportar → importar”.
El scraper: programar mi propia salida de emergencia
Escribí un scraper de Node.js a medida. Objetivo: convertir un sitio viejo y bloqueado en un dataset limpio.
Respetamos la estructura original (encabezados, listas, enlaces) para asegurar un render fiel.
// korail-scraper/scrape-to-json.js (extracto condensado)
import { chromium } from 'playwright'
import TurndownService from 'turndown'
import { gfm } from 'turndown-plugin-gfm'
// 1) Obtener HTML dinámico
async function renderPage(url) {
const browser = await chromium.launch({ headless: true })
const page = await browser.newPage()
await page.setUserAgent('Mozilla/5.0 KorailScraper/1.0')
await page.goto(url, { waitUntil: 'networkidle' })
await page.waitForTimeout(1000)
const html = await page.content()
const title = await page.title()
await browser.close()
return { html, title }
}
// 2) Fallback: <article> → si no, <main> → si no, <body> limpio
function extractMainHtml(fullHtml) {
const bodyStart = fullHtml.indexOf('<body')
const bodyEnd = fullHtml.lastIndexOf('</body>')
const body = bodyStart !== -1 && bodyEnd !== -1 ? fullHtml.slice(bodyStart, bodyEnd + 7) : fullHtml
const pick = (re) => (body.match(re)?.[0] || '')
const article = pick(/<article[\s\S]*?<\/article>/i)
if (article) return article
const main = pick(/<main[\s\S]*?<\/main>/i)
if (main) return main
return body.replace(/^<body[^>]*>/i, '').replace(/<\/body>$/i, '')
}
// 3) Convertir HTML → Markdown preservando encabezados/listas/enlaces
function htmlToMarkdown(innerHtml) {
const turndown = new TurndownService({ headingStyle: 'atx', codeBlockStyle: 'fenced' })
turndown.use(gfm)
return turndown.turndown(innerHtml)
}
# URL única
node scrape-to-json.js --url https://www.hindouisme.org/quien-es-ganesha
# Archivo de URLs + base
node scrape-to-json.js --file urls.txt --base https://www.hindouisme.org
Stack utilizada
- Puppeteer — obtener HTML dinámico (imágenes lazy, contenido con scripts)
- Cheerio — parsear/limpiar el DOM antes del export (quitar estilos inline/wrappers)
- Turndown + GFM — HTML → Markdown conservando encabezados, listas, enlaces
- Exportación final en JSON
Pasos del proceso
-
Crawlear todas las URLs
- El script escanea el sitemap cuando existe; si no, recorre el sitio recursivamente vía enlaces internos.
- Resultado: una lista exhaustiva de ~500 páginas.
-
Extracción de contenido
- Para cada página: título, cuerpo de texto, imágenes, enlaces internos/externos.
- Limpieza de etiquetas (
<div style="…">→ eliminado; se conservan títulos, párrafos, listas, imágenes).
-
Estructuración en JSON Ejemplo de salida:
{ "url": "https://www.hindouisme.org/quien-es-ganesha", "title": "¿Quién es Ganesha?", "content": "<h1>…</h1><p>…</p>", "images": [ {"src": "/uploads/ganesha.jpg", "alt": "Ganesha"}, {"src": "/uploads/temple.jpg", "alt": "Templo hindú"} ], "links": [ "https://www.hindouisme.org/dharma", "https://www.hindouisme.org/karma" ] }
👉 En este punto, tenía una fotografía completa del sitio: limpia, clara, aprovechable.
El importador de Korail
Una vez generado el dataset, había que ingerirlo en Korail. Ahí entra en juego el importador de Korail.
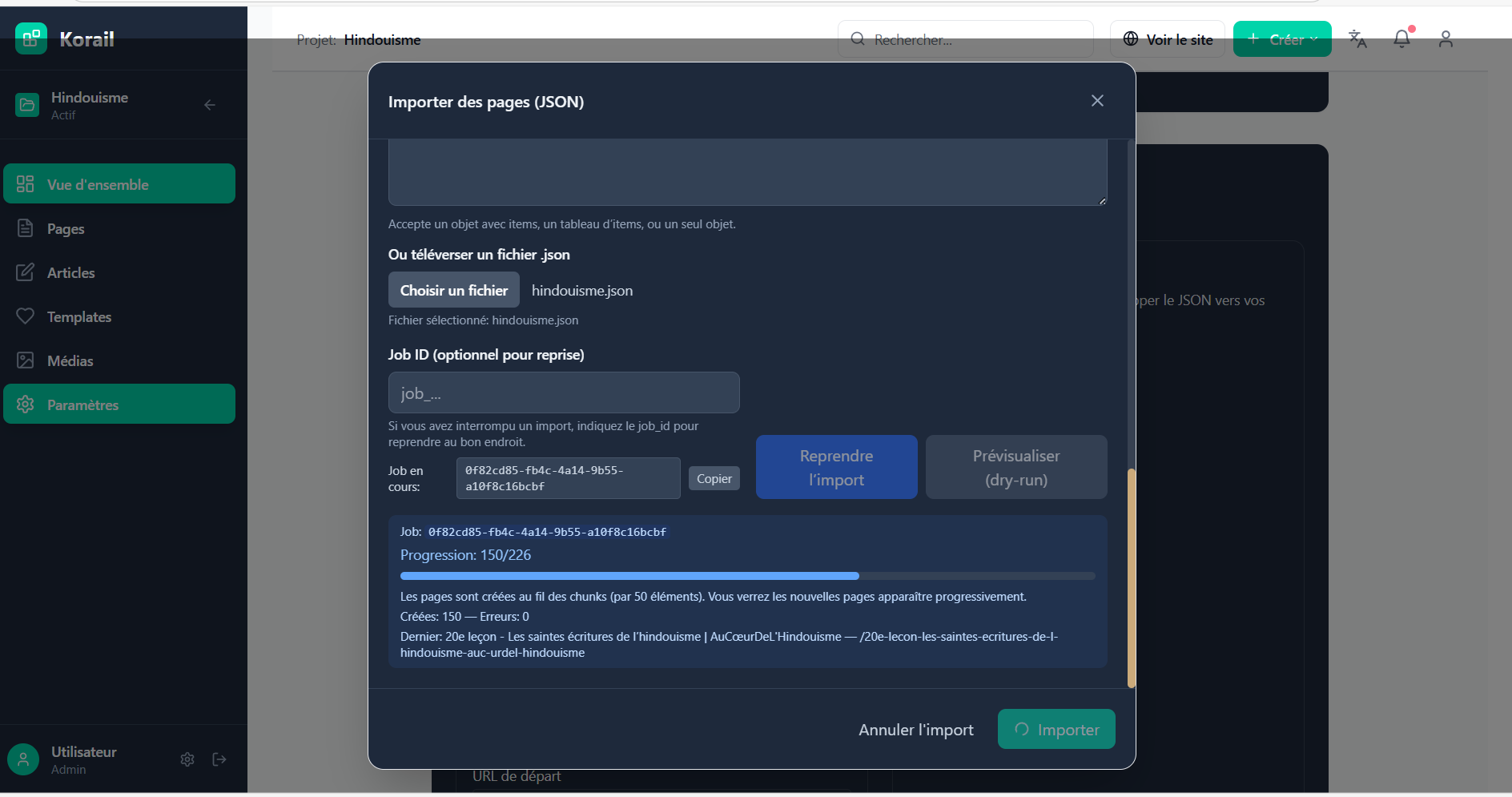
Pasos de la importación
-
Lectura del JSON: cada objeto se interpreta como una futura página/artículo.
-
Inserción en Supabase (mi Postgres):
- Tabla
pages(oposts) →title,slug,content,status. - Tabla
media→ descarga de imágenes en local + subida a Supabase Storage. - Tabla
links→ conservación de relaciones internas.
- Tabla
-
Conversión a bloques de React:
- Cada página se divide en bloques (
HeadingBlock,ParagraphBlock,ImageBlock, etc.). - Resultado: el contenido se vuelve editable bloque a bloque en Korail.
- Cada página se divide en bloques (
-
Optimización automática:
- Imágenes → renombradas, comprimidas, con
altgenerado por IA (Visión). - SEO → generación de
meta_titleymeta_descriptioncon GPT‑4 mini. - URLs → reescritas de forma limpia, sin
/page-123.
- Imágenes → renombradas, comprimidas, con
Ejemplo concreto
Una vieja página de Wix:
<div style="font-size:22px;color:red">¿Quién es Ganesha?</div>
<p>Ganesha es …</p>
→ se convierte en Korail:
{
"blocks": [
{"type": "HeadingBlock", "content": "¿Quién es Ganesha?", "level": 1},
{"type": "ParagraphBlock", "content": "Ganesha es …"}
]
}
Y sobre todo: editable directamente en el panel de Korail.
Por qué esto lo cambia todo
No es solo una importación única. Cada línea del scraper y del importador ahora está integrada en Korail.
Resultado:
- Puedo importar un sitio de Wix, WordPress o Squarespace en minutos.
- El contenido queda estructurado en bloques React, fácil de editar.
- Las imágenes se almacenan correctamente con títulos/alt automáticos.
- El sitio queda listo para SEO desde el día 1.
👉 Hindouisme.org es solo el primer ejemplo. Cualquiera puede probar Korail en mykorail.com y ver cómo este flujo de trabajo simplifica la vida.
Parte 3: ¿y ahora?
Ahora que el contenido está importado en Korail, empieza el verdadero reto: ¿cómo dar una arquitectura clara a más de 700 páginas?
- Repensar la navegación: categorías, subsecciones, páginas pilar.
- Evitar el efecto laberinto donde el usuario se pierde en decenas de menús.
- Sentar las bases de la búsqueda vectorial — no para reemplazar la navegación, sino para potenciarla, ofreciendo dos puertas de entrada complementarias:
- Explorar por estructura (secciones claras, jerarquía lógica).
- Explorar por sentido (preguntar libremente y obtener una respuesta precisa).
👉 Eso es exactamente lo que exploraré en la Parte 3: cómo transformar una masa de contenido en un sitio legible, lógico e inteligente, gracias a una arquitectura repensada y aumentada por la búsqueda vectorial.
📅 Primera demo pública: agosto de 2025 🎯 Objetivo: mostrar hindouisme.org importado en Korail, con navegación repensada + primeras pruebas vectoriales.
Mientras tanto, explora Korail y sigue el blog: mykorail.com/korail/es/blog.
Artículos relacionados
Cuando 5000 años de historia se encuentran con las nuevas tecnologías — Parte 1
Reconstruir hindouisme.org y crear Korail: un CMS nativo vectorial con React, Supabase, SEO, rendimiento y simplicidad.
Por qué dejé WordPress (y ni hablemos de Wix)
Por qué ahora construyo todos mis sitios con Next.js, React, Vercel y Supabase
Por qué creé Korail
Por qué creé Korail, con búsqueda vectorial integrada al estilo Perplexity.
Marie Fa
Desarrolladora full-stack de Québec, radicada en Bacalar — navego entre aguas turquesa y líneas de código.
Fundadora de Murmure y Korail, SocialRally y Adorable Sailing.